


The two modes of biotech data

This week, I’m going to start exploring different corners of the recently launched Biotech Reference Stack. But first a quick plug: I just started a second newsletter about writing in a way that people will read and share (Viral) about complex technical topics like biotech data management (Esoterica). If you want to learn all the tricks I’ve figured out while writing Scaling Biotech, head over there and subscribe. And if you don’t want to learn that, stay tuned for the content you’ve come to expect on here.
Now to the Reference Stack:
This week, I want to dig into a distinction that starts to matter when a biotech wants to make decisions based on multiple different types of readouts/assays. I see this most often with the hit/lead dashboard where teams need to consider multiple readouts before deciding which compound/sequence/etc. to invest more time and energy into.
The distinction is between the Data Lake in the Data Analysis module of the Reference Stack and the Database in the Decision Making module. And the difference is all about the nature of the data than, not the technical implementation.
The Data Lake treats each readout as an independent package that goes through a series of discrete, internal transformations. The Database merges the final forms of these datasets together in a way that emphasizes the connections between them.
I don’t normally go through the trouble of making diagrams for these weekly newsletters, but I’ve used this with internal/client presentations enough times that I happen to have it lying around:
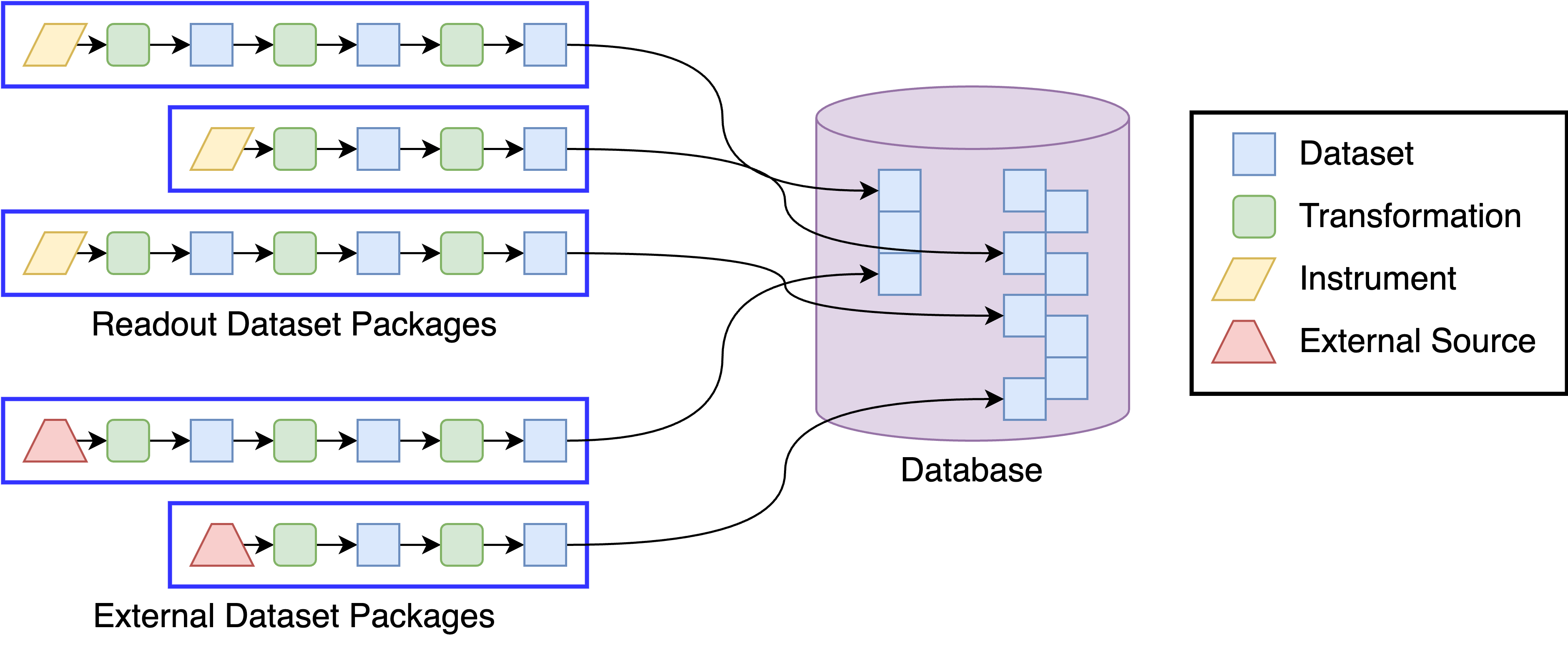
As the diagram suggests, I like to think of the Database as stacking datasets with compatible schemas from the Data Lake into a single table. And I say compatible schemas instead of the same schema because in some cases different readouts may populate different columns in the same table. Otherwise, you wouldn’t be able to compare across assays in your hit dashboard, or whatever that core decision making tool is.
This distinction is important both because you’ll need different tools and processes for each side, and because you’ll need to explicitly define how data gets from one to the other. Getting those schemas to be compatible is a complex and subtle problem, particularly as your library of assays grows. I know a number of (very engineer-heavy) biotechs that have written custom systems to manage this. But for the teams that don’t have that bandwidth and expertise, someone usually ends up manually copying the data between spreadsheets. (This is bad.)
My main goal for the Reference Stack is to help biotech teams replace these time consuming and error prone manual processes with off-the-shelf software. And the Stack currently lists three options that explicitly address this one (Kaleidoscope, Ontologic and Sphinx) and a number of others that provide more general purpose tools to enable it. (If you’re building something that does this but isn’t on there yet, you can request information about adding it.)
If this is the kind of thing your team has been struggling with, hopefully the Reference Stack will help you figure it out. (And if there are things that would make the site more helpful, I’m always looking for feedback.)
For the next few weeks, I’ll continue diving into different corners of the Reference Stack. So stay tuned!
Thanks for reading this week’s Scaling Biotech! I really appreciate your continued support, and I read every comment and reply.
As a reminder, I offer several services to help connect biotech teams with tools, practices and expertise to make their organizations more data driven.
The Biotech Reference Stack is a website designed to help biotech data teams identify the tools they need and figure out how to put them together.
For help navigating the Reference Stack, sign up for a free consultation call to clarify a problem you're facing and identify the best options to evaluate.
Or if you’re building software that makes biotech more data driven, find out how to add your app to the Reference Stack.